Back-pressure avec RxJava

Avec RxJava 1, on manipulait des observables et des observers.
Puis est arrivé RxJava 2 (en 2016) avec une grande nouveauté, le support de la back-pressure.
Pour ça, la classe Flowable est apparue, avec un aspect très proche de Observable, mais un comportement très différent.
Une fois qu’on a dit ça, il va falloir qu’on voit ce que signifie back-pressure et qu’on le mette en lumière avec un exemple simple. Et c’est justement à cause de la simplicité excessive de mon exemple que j’ai dû slalomer dans quelques subtilités de RxJava.
Principe du back-pressure
Cette notion existait en mécanique des fluides, bien avant RxJava. On la retrouve dans les moteurs thermiques, en génie chimique, en sidérurgie,… et dans tous les domaines où il y a des écoulements et des pressions à équilibrer.
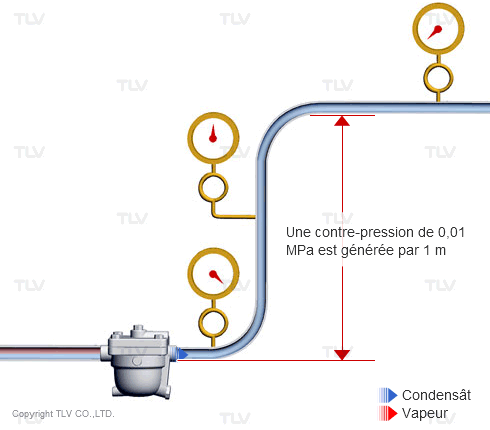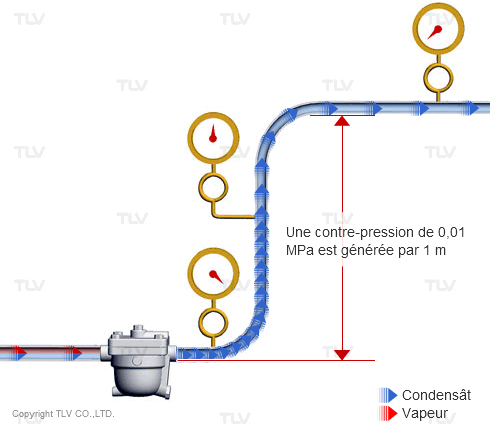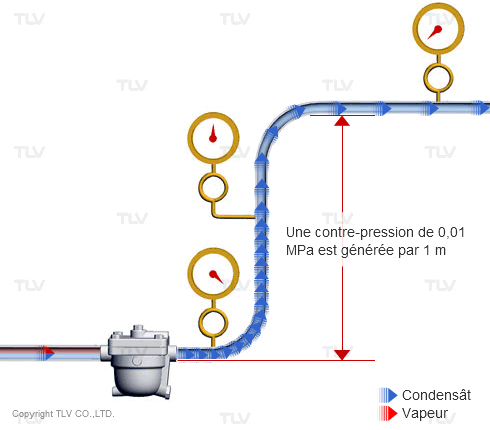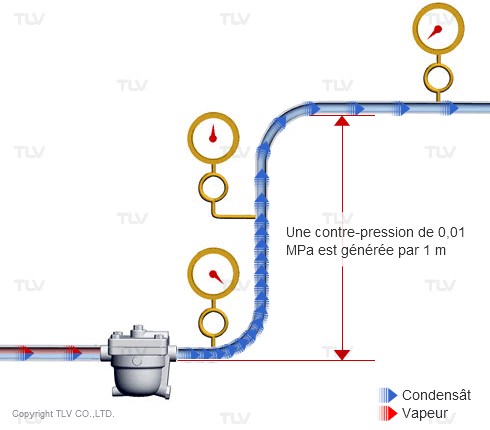
La traduction française de back-pressure est "contre-pression" ou "pression aval", par opposition à la "pression amont" qui représente le fonctionnement classique.
Et RxJava là-dedans ? C’est la même logique, en remplaçant le fluide par un flux de données.
Habituellement, si on a un flux de données entre un objet A et un objet B, la pression et le débit sont imposés par A, l’objet amont. Le risque encourru, c’est la saturation de B si ce dernier n’est pas capable de consommer assez rapidement les données.

Si le flux est piloté par l’aval, il devient plus fluide.

RxJava : Observable contre Flowable

RxJava supporte la pression aval depuis la version 2, avec l’introduction de la classe Flowable.
Comme pour Observable, une instance de Flowable est un producteur de données.
La principale différence, c’est le support de la pression aval.
J’ai voulu mettre en lumière la différence de fonctionnement en m’appuyant sur un exemple le plus simple possible. D’un coté, il y a un producteur qui produit des données à une vitesse élevée. De l’autre coté, un observateur les consomme plus lentement. Des traces permettent de suivre la production et la consommation des objets, ainsi que les temps de traitement et la consommation en mémoire heap.
RxJava en front-pressure
Dans la première version de l’exemple, le producteur est un observable.
En l’exécutant avec une quantité limitée de mémoire (-Xmx64m), le résultat attendu est une saturation de la mémoire.
Pour la production de données, j’ai opté pour un observable de type intervalle d’entiers (Observable.range(0, 1_000)), avec une transformation en données plus lourdes (map(Data::new)), pour saturer la mémoire de façon plus tangible.
class Data {
final Byte[] bytes;
final Long value;
public Data(Long value) {
this.value = value;
bytes = new Byte[50_000];
sleep(10);
}
}observable = Observable
.range(0, 1_000)
.map(Data::new);Enfin, j’ai souscrit à cet observable avec un observer plus lent que la production.
observable.subscribe( data -> sleep(data.value == 0 ? 500 : 50) );Le résultat est décevant : ça fonctionne sans erreur. Il n’y a aucune accumulation des objets, chaque objet produit est consommé avant la production de l’objet suivant.
554 - [main] New data: 0 (12 MB)
1074 - [main] Handled: 0 (12 MB)
1077 - [main] New data: 1 (12 MB)
1138 - [main] Handled: 1 (12 MB)
1139 - [main] New data: 2 (12 MB)
1200 - [main] Handled: 2 (13 MB)
1200 - [main] New data: 3 (13 MB)Par ailleurs, on constate que tout se passe de façon synchrone, dans le thread main.
C’est le fonctionnement par défaut de la méthode range(…) qui est un peu simpliste pour voir les effets de la front-pressure.
RxJava en front-pressure, 2° essai
L’appel de observeOn(…) permet de traiter l'observable de façon asynchrone en utilisant un pool de threads.
observable = Observable
.range(0, 1_000)
.map(Data::new)
.observeOn(Schedulers.computation());En exécutant ça avec la même quantité limitée de mémoire (-Xmx64m), le résultat a été bien plus parlant.
Aux alentours de la 350ème instance de Data, on a eu une erreur de mémoire, due à la saturation de la heap.
java.lang.OutOfMemoryError: Java heap spaceCe résultat est dû au fait que Observable fonctionne par front-pressure.
Le producteur ne se préoccupe pas de la vitesse de consommation, il produit ce qu’on lui a demandé, et les objets s’accumulent.
Les traces montrent qu’on a une première phase où on n’a que de la production.
602 - [main] New data: 0 (15 MB)
620 - [main] New data: 1 (15 MB)
631 - [main] New data: 2 (16 MB)
641 - [main] New data: 3 (16 MB)
652 - [main] New data: 4 (16 MB)
...Puis des alternances, avec environs 1 consommation pour 5 productions.
...
3343 - [main] New data: 250 (49 MB)
3354 - [main] New data: 251 (49 MB)
3364 - [main] New data: 252 (49 MB)
3374 - [RxComputationThreadPool-1] Handled: 44 (50 MB)
3381 - [main] New data: 253 (50 MB)
3392 - [main] New data: 254 (50 MB)
...Dans cette alternance déséquilibrée, le surplus de production fait augmenter l’utilisation de mémoire heap jusqu’à saturation.
RxJava en back-pressure
Voyons maintenant comment se comporte un flowable dans la même situation. Ça devrait mieux se passer puisqu’il supporte la fameuse back-pressure.
Mon code ressemble beaucoup à l’exemple précédent, avec le remplacement de Observable par Flowable.
J’ai reconduit l’appel à observeOn(…) pour les mêmes raisons que pour Observable.
Sans lui, le fonctionnement reste synchrone.
flowable = Flowable
.rangeLong(0, 1_000)
.map(Data::new)
.observeOn(Schedulers.computation());La façon de consommer les données est absolument similaire.
flowable.subscribe( data -> sleep(data.value == 0 ? 500 : 50) );Avec la même quantité limitée de mémoire (-Xmx64m), on voit que le traitement va au bout sans saturation.
Les traces montrent que les premières secondes se passent comme pour l'observable : une première phase où on n’a que de la production, puis 1 consommation pour 4 ou 5 productions.
555 - [main] New data: 0 (14 MB)
578 - [main] New data: 1 (14 MB)
589 - [main] New data: 2 (14 MB)
600 - [main] New data: 3 (14 MB)
611 - [main] New data: 4 (15 MB)
621 - [main] New data: 5 (15 MB)
632 - [main] New data: 6 (15 MB)
...
1200 - [main] New data: 57 (14 MB)
1211 - [main] New data: 58 (16 MB)
1222 - [main] New data: 59 (16 MB)
1230 - [RxComputationThreadPool-1] Handled: 3 (16 MB)
1232 - [main] New data: 60 (16 MB)
1243 - [main] New data: 61 (16 MB)
...Au bout de 2 secondes, le foncitonnement change. On a alors des gros blocs de consommation en alternance avec des gros blocs de production. Et, alors qu’au début la production se passait dans le thread main, dorénavant elle se fait dans le thread du pool.
...
52515 - [RxComputationThreadPool-1] Handled: 862 (33 MB)
52565 - [RxComputationThreadPool-1] Handled: 863 (33 MB)
52565 - [RxComputationThreadPool-1] New data: 896 (33 MB)
52576 - [RxComputationThreadPool-1] New data: 897 (33 MB)
...
58450 - [RxComputationThreadPool-1] New data: 998 (52 MB)
58461 - [RxComputationThreadPool-1] New data: 999 (52 MB)
58521 - [RxComputationThreadPool-1] Handled: 960 (52 MB)
58571 - [RxComputationThreadPool-1] Handled: 961 (52 MB)
...
60430 - [RxComputationThreadPool-1] Handled: 998 (52 MB)
60480 - [RxComputationThreadPool-1] Handled: 999 (52 MB)
60481 - [RxComputationThreadPool-1] Completed (52 MB)Il va falloir approfondir un peu le fonctionnement du flowable pour comprendre sa logique. Toujours est-il que le traitement est passé en intégralité, sans saturation, sans erreur, comme on l’attendait du mode back-pressure
Explications
Revenons sur le profil de fonctionnement du flowable.
Dans notre exemple, il envoie les objets vers un buffer, qui est initialisé à l’appel de observesOn(…).
A partir de la souscription, le flowable produit depuis le thread principal jusqu’à la première saturation de ce buffer, à 128 éléments. Puis il se met en pause jusqu’à ce que les trois quarts des éléments soient consommées.
A partir de là, des blocs de production de 96 éléments (128 - 128 >> 2) et des blocs de consommation de 96 éléments alternent.
Il est possible de modifier la taille du buffer et de ces paquets, pour s’adapter à la consommation mémoire souhaitée.
flowable = Flowable
.rangeLong(0, 1_000)
.map(Data::new)
.observeOn(Schedulers.computation(), false, 32);Voila. Sur la base d’un simple compteur, on arrive à mettre en lumière la notion de back-pressure avec RxJava.
Alexis Hassler
J'ai créé la société Sewatech en 2005, pour y exercer mon métier de développeur full stack, à dominante back end.
Vous pouvez me contacter si vous cherchez un développeur indépendant expérimenté (plus de 25 ans d'expérience) pour intégrer votre équipe de projet. Je peux aussi intervenir pour un audit ou une mission de conseil.
Enfin, je donne des formations sur Spring, Vert.x, WildFly,... en intra sur site ou à distance.